
在人工智能技术的蓬勃发展中,大语言模型正成为推动技术革新的重要力量。近日,人工智能及大数据科技企业合合信息发布了其自主研发的文本向量化模型acge_text_embedding(简称“acge模型”),并在权威的中文语义向量评测基准C-MTEB(中文大规模文本嵌入基准)上取得了第一名的优异成绩。
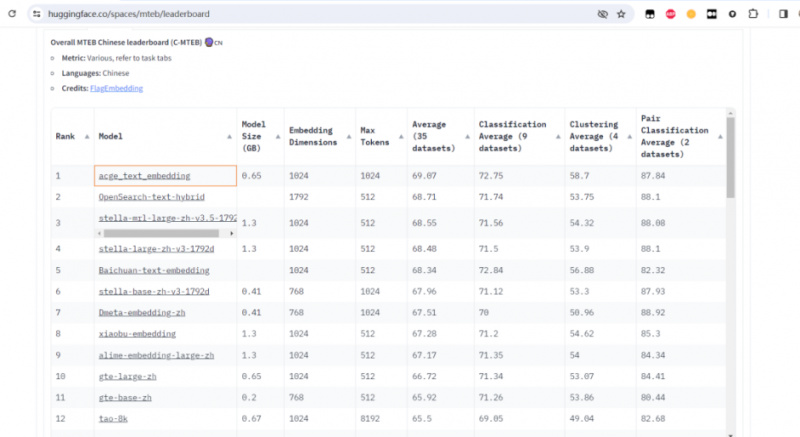
C-MTEB作为业内公认的中文语义向量评测基准,涵盖了分类、聚类、检索、排序、文本相似度、STS等六大经典任务,共包含35个数据集,为评估中文语义向量的全面性和可靠性提供了可靠的实验平台。合合信息的acge模型能够在如此全面的评测中脱颖而出,充分证明了其卓越的性能和广泛的应用潜力。
Embedding模型作为大语言模型应用落地的关键支撑,通过理解查询的深层含义和上下文,能够显著提高搜索和问答的质量、效率和准确性。在互联网信息爆炸的时代,Embedding模型的重要性不言而喻。据合合信息技术团队成员介绍,相比于传统的预训练或微调垂直领域模型,acge模型支持在不同场景下构建通用分类模型、提升长文档信息抽取精度,且应用成本相对较低,可帮助大模型在多个行业中快速创造价值,推动科技创新和产业升级,为构建新质生产力提供强有力的技术支持。
具体实践上,为做好不同任务的针对性学习,团队使用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,使模型训练迭代能够达到相对优秀的收敛空间;运用MRL技术,实现一次训练,获取不同维度的表征。
值得一提的是,acge模型在体积和性能上均表现出色。相比于目前C-MTEB榜单上排名前五的开源模型,acge模型较小,占用资源少,输入文本长度达到1024,满足了绝大部分场景的需求。此外,acge模型还支持可变输出维度,企业可以根据具体场景去合理分配资源,实现更高效的资源利用。
未来,合合信息将继续致力于人工智能技术的研发和应用,为全球C端用户和多元行业B端客户提供更加数字化、智能化的产品和服务,推动科技创新和产业升级,为构建新质生产力贡献自己的力量。
免责声明:本文为本网站出于传播商业信息之目的进行转载发布,不代表本网站的观点及立场。本文所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。本网站对此咨询文字、图片等所有信息的真实性不作任何保证或承诺,亦不构成任何购买、投资等建议,据此操作者风险自担。